
Training deep neural networks involves a challenging optimization landscape with gradients that guide the learning process. The scale of these gradients significantly influences the stability and efficiency of training. Large gradients can cause erratic updates, potentially leading to divergent behavior, while small gradients may slow down or halt learning. Layer normalization (LayerNorm) is a technique that addresses these issues by standardizing activations within each layer, allowing for smoother gradient flow and improving overall training stability. This article delves into the technical aspects of layer normalization, highlighting its role in models like AlbertAGPT with concrete examples.
Layer Normalization: Mathematical Formulation
Layer normalization, introduced by Ba, Kiros, and Hinton in 2016, normalizes the activations within a neural layer by adjusting the mean and variance of each neuron’s activations across a single input. Unlike batch normalization, which normalizes across the batch dimension, layer normalization works across the features of each input individually, making it particularly effective in models where the batch size is small or varies, such as in natural language processing (NLP) models that handle variable-length sequences.
Mathematically, for a given input vector x=[x1,x2,…,xn]x = [x_1, x_2, …, x_n]x=[x1,x2,…,xn] within a layer, layer normalization computes the mean μ and variance σ2:
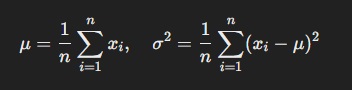
The normalized output
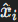
for each neuron is then calculated as:
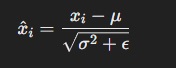
where ϵ\epsilonϵ is a small constant added for numerical stability. Layer normalization further scales and shifts these normalized values using learnable parameters γ (scale) and β (shift):
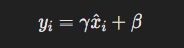
This approach allows the model to retain the expressiveness of its activations while maintaining stable distributions during training.
Impact on Gradient Flow and Training Stability
In deep networks, gradient flow can be disrupted by issues such as vanishing or exploding gradients. By standardizing activations within each layer, layer normalization helps maintain the gradients within a reasonable range during backpropagation. For instance, consider a deep feedforward network trained on a complex task like language modeling. Without normalization, deeper layers might produce highly varied outputs, leading to unstable gradients that oscillate or diminish across layers.
LayerNorm smooths the optimization landscape by keeping gradients more consistent, which is especially beneficial in models that stack many layers, such as transformers. In transformer architectures, layer normalization is applied after the self-attention and feedforward sub-layers, ensuring that the gradients do not vary wildly between layers. This consistent scaling prevents the network from making overly aggressive or overly cautious updates, which could destabilize training.
Internal Covariate Shift Reduction and Learning Efficiency
Layer normalization addresses the issue of internal covariate shift—the change in the distribution of layer inputs as network parameters are updated. This shift forces the model to continually adapt to new data distributions, slowing down the training process. For example, in recurrent neural networks (RNNs) like LSTMs, where hidden state dynamics evolve over time, LayerNorm can dramatically reduce the covariate shift, stabilizing the learning process.
Consider an RNN processing a sequence of time steps where each step depends on the outputs of the previous step. Without normalization, the hidden states can exhibit high variance across time, complicating the learning of long-term dependencies. Layer normalization addresses this by stabilizing the outputs of each time step, ensuring that the model remains sensitive to new information without losing track of past data. This results in more efficient training, as evidenced by faster convergence rates and improved performance on tasks like sequence generation and machine translation.
Preventing Error Accumulation in Deep Networks
As information flows through the layers of a deep network, small errors can compound, leading to significant deviations in the model’s output. This problem, particularly acute in architectures with many layers, is alleviated by layer normalization. For example, in deep convolutional networks used for image recognition, normalization helps to manage the variability in feature activations caused by different input images.
In convolutional neural networks (CNNs), convolutional layers extract spatial hierarchies of features from the input data. Without normalization, the activations of deeper layers can grow disproportionately, leading to sharp gradients that destabilize the training. LayerNorm mitigates this by maintaining consistent activations across all neurons in each layer, thereby reducing the potential for error accumulation. This approach is essential in maintaining the model’s capacity to learn complex, multi-scale features without degradation in performance.
Application in Transformer Models
In transformer architectures, such as BERT, GPT, and AlbertAGPT, layer normalization plays a pivotal role by normalizing the activations after each sub-layer operation, including the self-attention and position-wise feedforward layers. The formula used in transformers integrates LayerNorm into the residual connections:
Output=LayerNorm(Input+SubLayer(Input))
This setup helps to stabilize the training of the highly expressive self-attention mechanisms, where the dynamic range of activations can vary significantly. For instance, in AlbertAGPT, which scales down the parameters while retaining performance, LayerNorm ensures that the smaller parameter space does not lead to overly aggressive learning rates or unstable gradient magnitudes.
AlbertAGPT’s Use of Layer Normalization
AlbertAGPT utilizes layer normalization extensively to manage the flow of information between its layers, enhancing training stability. In this architecture, LayerNorm is applied after the feedforward and attention mechanisms within each transformer block. By normalizing the outputs at each stage, AlbertAGPT effectively balances the contributions of each layer, ensuring that no single layer disproportionately influences the model’s learning dynamics.
For example, during the training of AlbertAGPT on large-scale datasets, the variability in sentence length and structure can cause instability if not properly managed. Layer normalization ensures that each token’s contextual representation is scaled appropriately, allowing the model to maintain a steady learning rate and prevent divergence, even when dealing with complex input sequences.
Managing Information Flow Between Layers
Layer normalization’s ability to maintain consistent activation scales directly impacts how information flows between layers. In deep networks, layer outputs can vary widely in scale due to the inherent differences in layer operations and activation functions. For instance, in NLP models using transformers, embedding layers produce outputs that need to be scaled appropriately for subsequent attention layers. LayerNorm maintains these activations within a range conducive to stable training.
In AlbertAGPT, the consistency provided by layer normalization across different layers ensures that the model can accurately propagate learned features from one layer to the next without distortion. This consistency is crucial for building hierarchical representations that capture long-term dependencies in data, such as the complex grammatical structures found in natural language.
Reducing Hyperparameter Sensitivity
Layer normalization also reduces sensitivity to hyperparameters such as learning rates, weight initialization, and batch sizes. This robustness is particularly valuable when dealing with large models where hyperparameter tuning is challenging. For instance, in traditional training scenarios without normalization, slight variations in learning rate can lead to drastic changes in convergence behavior. LayerNorm mitigates this by standardizing layer activations, allowing for more lenient and less critical hyperparameter choices.
Experimental results from models like AlbertAGPT demonstrate that with layer normalization, training can proceed smoothly across a wider range of learning rates, reducing the trial-and-error process often associated with deep learning. This flexibility is crucial for optimizing models efficiently, especially in large-scale settings.
Enhanced Generalization and Regularization
Layer normalization has an implicit regularization effect, which can enhance the generalization of neural networks. By maintaining consistent activation distributions, LayerNorm helps prevent overfitting, a common problem in deep networks with high capacity. For instance, in transformer-based language models, where millions of parameters are tuned on vast corpora, normalization helps constrain the model’s learning capacity, guiding it towards more robust solutions.
Empirical studies have shown that models utilizing LayerNorm tend to perform better on unseen data compared to those without, highlighting its role as a regularization technique. In AlbertAGPT, this results in a model that not only learns effectively during training but also maintains performance during inference on previously unseen inputs.
Comparison with Other Normalization Techniques
While layer normalization shares some conceptual similarities with batch normalization (BatchNorm), it is uniquely suited to scenarios where batch-level statistics are not easily computed or relevant. BatchNorm normalizes activations using statistics computed across the entire batch, making it less effective in sequential tasks where each input can differ significantly in size or structure. For instance, in RNNs processing variable-length sequences, BatchNorm can disrupt temporal dependencies, whereas LayerNorm operates independently of the batch dimension.
In AlbertAGPT, the sequential and often variable nature of inputs makes LayerNorm an optimal choice, as it provides consistent normalization across diverse inputs without relying on batch statistics. This independence allows for more reliable training, particularly in low-resource settings where batch sizes cannot be guaranteed.
Future Directions in Layer Normalization Research
Ongoing research in normalization techniques explores the integration of LayerNorm with other methods, such as group normalization and instance normalization, to further enhance training stability. New approaches are being developed to fine-tune the scaling and shifting parameters dynamically, allowing for adaptive normalization that responds to changing training conditions. These advancements could further improve the performance of large-scale models like AlbertAGPT.
As neural architectures continue to grow in complexity, the principles underlying layer normalization will be crucial in maintaining training efficiency and stability. Future models may leverage adaptive layer normalization techniques that optimize the balance between stability and flexibility, unlocking new frontiers in artificial intelligence research.
Conclusion
Layer normalization is a powerful tool that stabilizes training in deep neural networks by managing gradient flow, reducing internal covariate shifts, and preventing error accumulation across layers. In advanced architectures like AlbertAGPT, it plays a crucial role in ensuring steady learning dynamics, making it an indispensable technique in the evolving landscape of deep learning.